Challenges of Deploying AI Models

Introduction
After periods of hype followed by several AI winters during the past half-century, we are experiencing an AI summer that might be here to stay. Machine learning now drives many real-world applications in the financial sector, ranging from fraud detection to credit scoring.
Innovation through AI promises considerable benefits for businesses and economies through its contributions to productivity and efficiency. At the same time, the potential challenges to adoption cannot be ignored. In the present paper, we focus on these from a model risk perspective. To make the discussion as concrete as possible, we will illustrate many aspects in the context of credit models. However, most of the conclusions can be straightforwardly translated to other applications that are relevant for the banking sector.
Table of contents
1. Introduction
2. The deployment challenge
3. Validating AI
4. Model Implementation Testing
5. Conclusion
2 See https://www.mckinsey.com/business-functions/risk/our-insights/the-value-in-digitally-transforming-credit-risk-management
3 See Cathy O’Neil, “Weapons of Math Destruction”, (2017) Penguin Books Ltd
4 Although ML (machine learning) is generally considered to be a subset of AI (artificial intelligence), we will use the terms interchangeably since most AI applications in banks simply leverage ML.
Since credit models play such an important role in a bank’s risk management, the introduction of AI leads to substantive improvements as was highlighted in a recent study by McKinsey.2 In this paper, Bahillo et al. reasoned that “credit risk costs can be reduced through the integration of new data sources and the application of advanced analytics techniques. These improvements generate richer insights for better risk decisions and ensure more effective and forward-looking credit risk monitoring. The use of machine-learning techniques, for example, can help banks improve the predictability of credit early-warning systems by up to 25 percent.”
However, these more sophisticated credit models as well as the higher degree of automated decision making come with two important challenges. First and foremost, there is the so-called deployment challenge, highlighting the difficulties in terms of HR, technical know-how and infrastructure required to productionize AI applications. Secondly, the so-called responsible AI challenge stresses the fact that higher sophistication of analytics also leads to different types of risk. See e.g. Cathy O’Neil’s book3 for an overview of some of the clearest dangers of applying ML4 without an appropriate model risk management framework in place.
In this article, we will focus on this first challenge while we will explore the responsible AI challenge in a forthcoming publication. The second chapter will highlight the main principles related to productionizing AI. As will be clear, these points can be addressed through a bank’s model risk management framework. However, due to the very nature of AI, such a framework has to be updated in order to deal with the complexities of ML algorithms. This is then analyzed in detail in Chapter 3.
The deployment challenge
Thanks to all the benefits that AI brings, many companies have a strong interest in embracing these technologies. Deploying AI, therefore, is a strategic decision with long term consequences, which requires a fairly large set of measures. The main ones are:
- Knowledge sharing: Since many AI innovations have a wide spectrum of applications, financial institutions should conduct initiatives in a manner that ensures the benefits can be shared by all. Topics such as explaining AI or quantifying algorithmic uncertainty have to be well understood across the enterprise in order to successfully adopt ML techniques. Hence, AI research in these topics will have to be shared by all.
- Data: Expanding available data sets, especially in areas where their use would drive wider benefits. Credit models often lack sufficiently large and unbiased training dataset. To give a few examples: low-default commercial credit portfolios are notoriously challenging since -by definition- the number of default events will be very low. On a similar topic, IFRS 9 guidelines require a so-called lifetime credit loss computations. For long-dated products, this means that banks have to gather very extensive datasets irrespective of the modelling approach. However, when looking at ML, typically large datasets are needed, which makes the introduction in this context more challenging. All this implies that banks should either attempt to gather larger datasets, e.g. via pooling or alternatively invest in techniques to generate synthetic data.5
- HR: Investing in AI-relevant human capital to broaden the talent base capable of creating and executing AI solutions is important. Even if a financial institution relies on a third-party vendor to supply AI algorithms, the bank should understand the risks involved. Quantitative analysts (quants) might have to be re-trained to deal with the increased adoption of AI.
- AI literacy: Encouraging increased AI literacy among business leaders and policymakers to guide informed decision making by the board. Leaders and regulators have to be trained on the benefits and pitfalls of AI.
The above general principles are all covered by a bank’s model risk management framework.
5 See e.g. the initiative by Capital One’s University of Illinois, Urbana-Champaign lab: https://medium.com/capital-one-tech/why-you-dont-necessarily-need-data-for-data-science-48d7bf503074
Indeed, when managing the risk associated with using mathematical models in decision making it is most important that everybody involved has a clear understanding of how and when the algorithm functions correctly. This covers the points above on knowledge sharing, HR and AI literacy.
Secondly, the accuracy of a model is highly correlated with the quality of the data that is fed into the algorithm. This implies that a model validator will also verify the data in great detail. This parallels the above point on data.
The cornerstone of any model risk management framework is the validation procedure since this guarantees that models are only deployed when certain quality standards are met. The validation process is also an opportunity to spread knowledge about the algorithm between the first and second line as well as towards the management level. In the next chapter, we therefore will review the various aspects of a model validation process and focus on the particularities related to analyzing artificial intelligence applications.
Validating AI
A typical validation process starts by determining the scope of the model as well as how it relates to other algorithms. After these introductory steps, a model validator analyzes various aspects of how model input data is managed and continues by measuring model performance. Before concluding, a proper validation process also studies the actual implementation as well as the level of documentation.
In a recent speech by the FED,6 it was suggested that both regulators and financial institutions should address the problem of validating AI applications by starting from what already exists. This is exactly what we will do in the present chapter.
Scope
A model is always used within a certain scope. E.g. we build credit models to deal with credit risk in mortgages for the Belgian market or create an interest rate curve generator to value EUR collateralized derivatives. When the scope changes, most model risk frameworks require a new validation.
In the context of machine learning applications, the scope of the model can be quite different from what validators are used to. As an example, when validating a chatbot that is used to assist clients in finding the best possible loan, the scope is rather wide. Hence, to make validation manageable, we suggest dissecting the algorithm in its individual components and validate those separately. E.g. in order to give proper advice to the client regarding the loan, the chatbot algorithm probably performs several analysis:
- Natural language processing to understand the user’s questions
- Data validation and cleaning to interpret the client’s input
- Forecasting (cash flows, creditworthiness, …) to be able to compute the best possible loan
Each of these components is a model on its own and requires a separate analysis.
This scoping exercise also implies that the validator is able to determine what are all the possible model output values, and this can be a complicated task (e.g. in the context of chatbots 7).
Because of this complexity, it is mandatory that an AI algorithm comes with a monitoring platform that is able to determine if the AI is operating within the proper scope. Such a framework would ensure that the chatbot’s answers are acceptable and would simultaneously determine that the client’s questions remain within scope (e.g. the chatbot should deflect a question on an insurance product when it is designed to deal with loans only).
See https://www.federalreserve.gov/newsevents/speech/brainard20181113a.htm
Dependent models
In quantitative finance, we often encounter cases where multiple models depend on each other. One of the most straightforward examples is a market risk model (such as VaR or ES) which uses PnL vectors as inputs. Those vectors themselves are being computed by valuation models and the latter depends on market data generation algorithms like curve construction and volatility surface calibration routines.
The main difference when dealing with ML is that very often the model will have a circular dependency. Indeed, many AI models are trained in a dynamic fashion as opposed to the more traditional credit or valuation models that are calibrated in an off-line regime. In dynamic training, the algorithm attempts to fit the data in small batches. This is an obvious advantage that the model will dynamically adapt to changing environments. However, simultaneously, it can make testing harder because the state in which the trained model will end up, will depend on the sequence in which training data was fed to the algorithm. To ensure reproducibility, a good approach is to implement the training procedure as a stateless operation. Concretely, this could be realized via a calibration routine that takes as input the previously calibrated model as well as the new training data and outputs the updated model. Such implementation would allow the validator to test various conditions and edge cases more easily. It would also help the developer to reproduce issues in the training.
7 See https://en.wikipedia.org/wiki/Tay_(bot) for an example of a chatbot experiment that spiralled out of control.
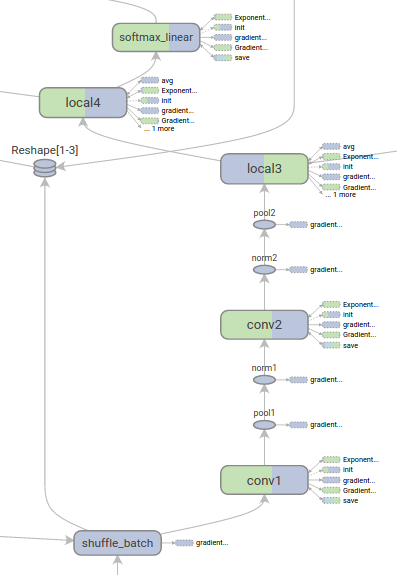
Documentation
Another key aspect of a validation exercise is to verify the level and quality of documentation. Many open-source libraries for machine learning are fairly well documented. However, when building an actual algorithm, a developer has to make a myriad of micro-decisions especially when determining the lay-out of the algorithms. A very powerful way of documenting those is to use diagrams. There is no unique solution yet on visualizing AI layouts, but in the context of neural networks, a few promising approaches already exist. One such example is Tensorboard’s graph visualization approach8 (see Figure to the left).
Another approach that is often used in the context of Convolutional Neural Networks is the so-called Krizhevsky diagrams (see below). Such diagrams depict the size of the various layers together with the convolution operators that map one layer onto the next.
Apart from the layout of the algorithm, also the data itself is often more intricate when compared to more traditional modelling approaches. Developers should therefore leverage dynamic inspection tools as a source of documentation that allows validators to analyze the data in greater detail. One open-source example is Google’s Facets.9
Another approach that is often used in the context of Convolutional Neural Networks is the so-called Krizhevsky diagrams (see below). Such diagrams depict the size of the various layers together with the convolution operators that map one layer onto the next.

Apart from the layout of the algorithm, also the data itself is often more intricate when compared to more traditional modelling approaches. Developers should therefore leverage
Data
As discussed in the previous Section 3.3 on Documentation, data plays an important role when building and validating machine learning algorithms, mostly due to the large number of samples as well as the dimensionality of the datasets. An additional challenge is the fact that AI often uses unstructured data.
When dealing with unstructured data, a model has an initial operation that maps it into a structured format. A well-known example is Word2vec,10 which is a model that maps a large corpus of text into a high-dimensional vector space. Vectors in the latter space then represent structured data that is fed into the actual algorithm. When validating such models, it is, therefore, crucial to analyze this preprocessing step in isolation, in order to understand the impact of changing the mapping methodology on the actual outcome of the algorithm.
Apart from this mapping, other procedures such as categorical encoding (to map discrete variables into continuous values) as well as normalization are important as well. We will however not handle these aspects in detail since they are not that different from the problems one encounters when dealing with more traditional algorithms. The only notable difference is that due to the typical size of the datasets, the transformations will require incremental processing of the data. This should be analyzed in detail by a careful validator.
9 See https://github.com/PAIR-code/facets
10 See https://en.wikipedia.org/wiki/Word2vec
Quality
Assuming that the data has been brought to a structured format, the next challenge is to verify the quality of the ML input data. As a model validator, it is important to first review what controls the developers have put in place to ensure this and secondly to analyze data quality independently. Given the size of the data, traditional anomaly detection methods might perform badly. One powerful approach is to use so-called autoencoders to detect a-typical data.
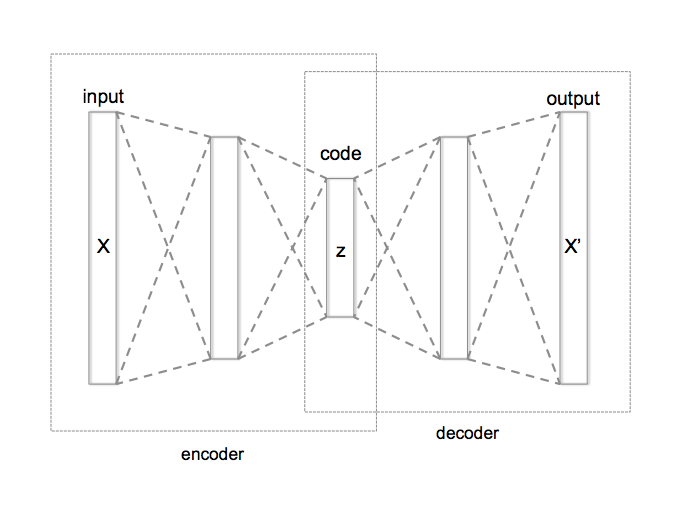
An autoencoder is a neural network that attempts to approximate the identity function. The algorithm’s input is a full data sample (such as the full feature vector that is input to a credit model for computing the probability of default). This input signal is then encoded into a
low-dimensional representation (the layer “z” in the Figure above) after which it is decoded to reconstruct the initial sample. If the reconstruction error (i.e. the difference between input and output) is larger than a threshold, the sample is considered to be a-typical.
By varying this threshold, a model validator can filter out more or fewer outlier points. This procedure is of interest when benchmarking the input data quality but can also be used to estimate model uncertainty as will be explained later on.
Representativeness
Traditional models used in finance often assume that the data generating distribution is time-invariant. Hence, when testing representativeness, one can rely on classical techniques
such as the Kolmogorov-Smirnov test to verify equality between training and scoring datasets.
Since ML algorithms, especially when trained in a dynamic fashion, are made to adapt to changing situations, this traditional approach to representativeness is not viable.
However, even if the algorithm can deal with non-stationary data, the model performance itself should remain constant over time. Hence, one approach towards this problem is to verify that performance metrics of the model remain constant both cross-sectionally as well as overtime. In addition, the scoring data should still be similar to the data that the model has been trained on. In other words, even for time-varying data, the distribution of the scoring data should be similar to a truncated version of the training data generating distribution.
Processing
Because ML algorithms often need big amounts of training data, developers might have to generate more samples by leveraging so-called data-augmentation techniques in order to enlarge the dataset. Two examples are:
- Exploiting symmetry in the dataset to generate new samples. E.g. if we assume that credit quality would not depend on the address of the client - i.e. when the probability of default would be translation invariant - we can generate other samples by taking an existing client and change the address
- Adding various levels of noise. E.g. when we use the income vs loan ratio as a feature, we can add a certain level of random noise to the ratio to generate new samples.
When validating data-augmentation techniques, it is important to verify that the underlying assumptions hold. One approach here is to look at the data, another solution is to build a benchmark model that can be accurately calibrated using the original data only and try to understand the observed differences.
Controls
Given the complexity of ML applications, a classical exhaustive model validation approach is insufficient. This implies that controls, i.e. continuous monitoring of the algorithms and the data pipelines become a critical aspect of the model. A validator, therefore, has the make sure that such controls are put in place before a model is productionized.
Model design and performance testing
Conceptual soundness
In the case of ML, conceptual soundness refers to three different aspects. First of all, the various algorithms should be properly implemented. Given the extensive use of existing open-source libraries with a very large and active community, this aspect can be considered to be managed by the community - although many validation teams will want to perform an independent check as well.
The second component is the methodology of how input features are engineered and selected. This includes the fact that input data should be properly normalized, discrete categories should
be correctly encoded (i.e. mapped to numerical attributes in a logical fashion), and features should not display large amounts of correlation. When engineering features, one needs to be mindful of the dimensionality (i.e. the units) of the input data. The good advice from more traditional engineering approaches to prefer dimensionless quantities still holds in the era of AI. A final measure of conceptual soundness is the care the developer displayed when splitting the data into train, validation and test sets. The train set is used to calibrate the model. The validation set allows for an independent evaluation of the model while tuning hyperparameters (these are the parameters determining the layout, fitting algorithm, etc.). Finally, the test set is used to evaluate the overall performance of the final model. Because of the huge amount of parameters, the risk for overfitting is often conceived to be larger than with more classical modelling approaches. Hence the need for proper separation of the datasets.
Model selection
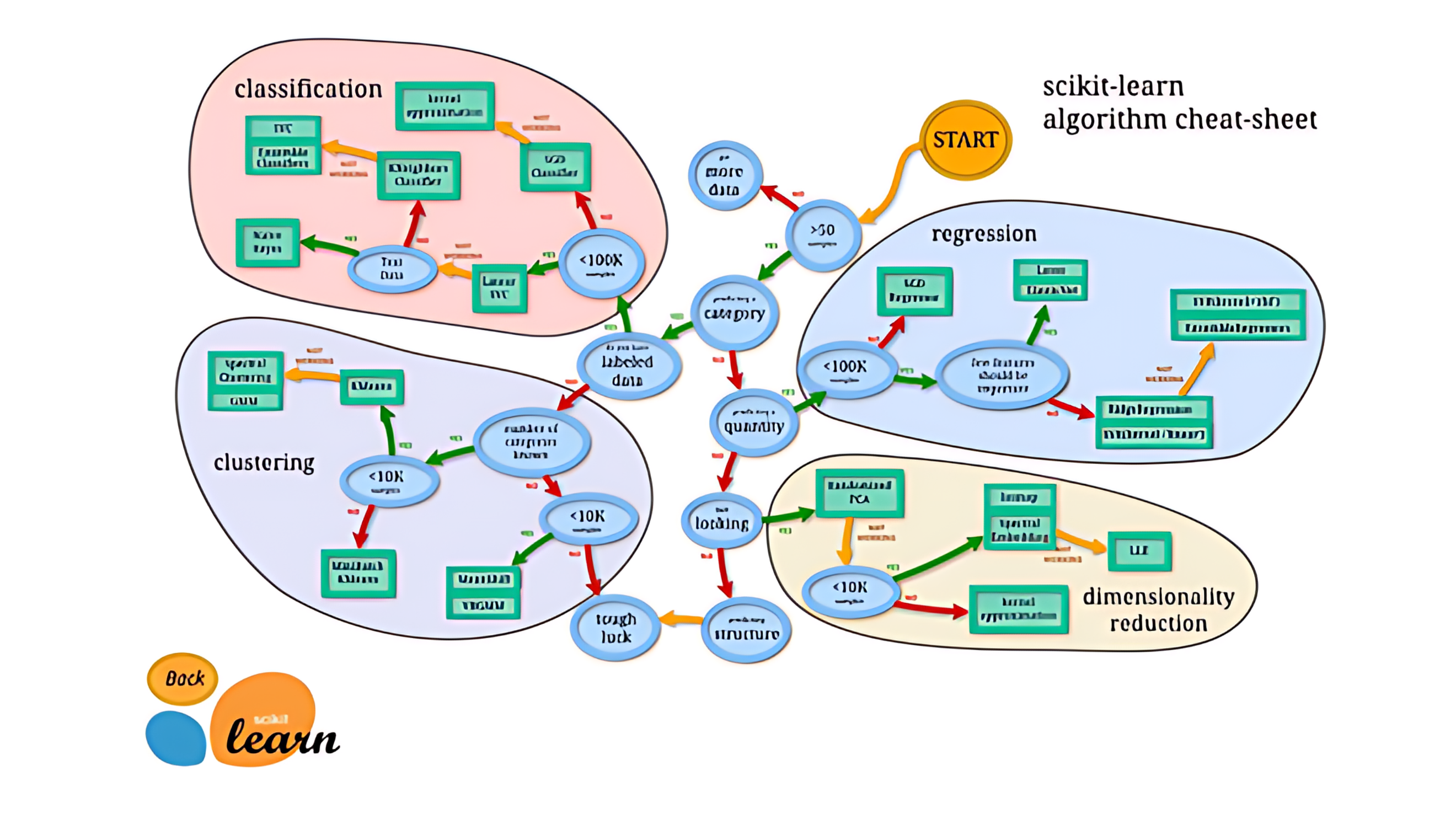
As with any model, when building a machine learning application, choosing the right algorithm is crucial. Compared to traditional valuation models, where the selection of the right diffusion process can be verified by analyzing historical time series of market data, selecting the right ML algorithm often depends on a set of heuristics. In order to develop an opinion on which algorithm to select, as a validator, one approach is to analyze many models. Using open-source libraries like TensorFlow,11 makes this easy once the data is brought into the right standardized format. An alternative approach is to borrow ideas on selecting ML algorithms from e.g. SciKit learn (or build your own selection process as part of an ML validation framework).12
Once the actual algorithm has been selected, the next step in the development process is to choose the right parameterization/layout. Indeed, as explained before, many ML algorithms have plenty of parameters that govern the training and configuration of the model itself. As an example, when building a neural network one has the specify the size, layout and connection topology of the neurons, the type of activation functions, the method for updating the weights, etc. Sometimes, parameters are chosen through a process called hyperparameter tuning. In this process, the developer trains the algorithm in different configurations in order to find the best possible approach. As a model validator, verifying the hyperparameter tuning algorithm is equally necessary to understand the stability of the resulting model, the details of the optimization function, the topology of the hyperparameter manifold, etc.
11 See https://www.tensorflow.org/
12 See https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
Backtesting
Analyzing model performance on previously unseen data is obviously crucial. As we already highlighted in section 3.5.1 on Conceptual Soundness, a proper separation between train, validation and test data, therefore, is important. To validate this in detail, one needs to gauge the implicit uncertainty caused by any particular choice of data separation. Hence a good approach is to consider several ways of separating the data, both randomly or in a structured fashion.
A backtest should then measure the variability in the training as well as the change in algorithm behaviour on scoring. The traditional measures used in outcome analysis can be used for this (see next section 3.5.4). In addition, a proper backtest also compares model performance to one or multiple alternative models (benchmarks, see section 3.5.5).
Outcome analysis
Due to the large amount of data and the complexity of ML models, simple summarizing metrics such as AUC and MSE are not sufficient. This is why various interactive performance analysis tools have been developed to assist validators (and developers) to increase their understanding of the model behaviour.13
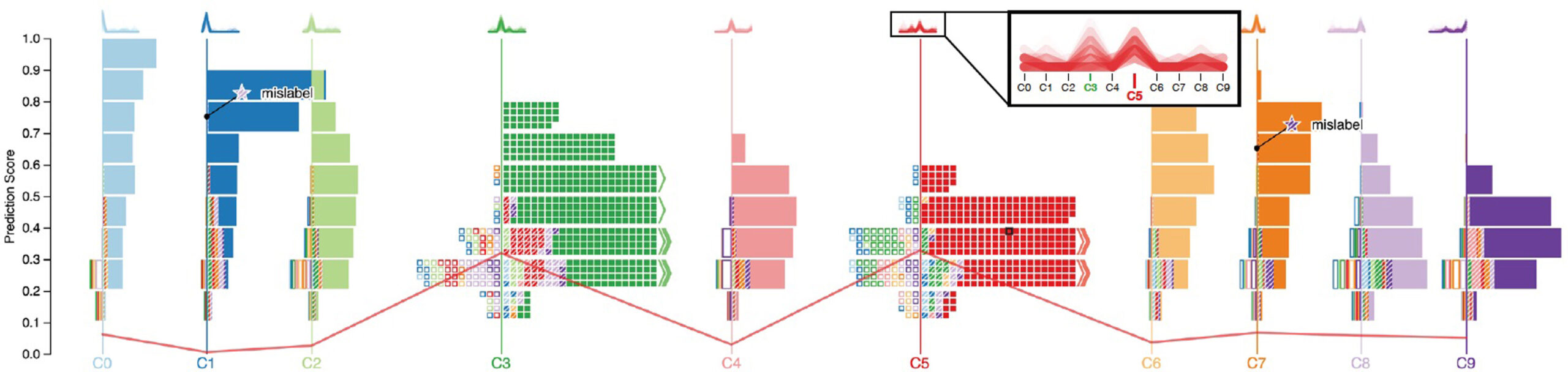
13 See S. Liu, “Towards better analysis of machine learning models: A visual analytics perspective”, (2017) Visual Informatics, Vol1, issue 1, https://www.sciencedirect.com/science/article/pii/S2468502X17300086
Squares14 is one such example that allows machine learning experts to troubleshoot classification algorithms efficiently. The tool shows prediction score distributions at multiple levels of detail. The classes, when expanded, are displayed as boxes. Each box represents a training or test sample. The colour of the box encodes the class label of the corresponding sample and the texture represents whether a sample is classified correctly (solid fill) or not (striped fill). The classes with the least number of details are displayed as stacks.
Benchmarking
Benchmarking is a useful tool to understand the impact of changing assumptions as well as to perceive the relative strengths and weaknesses of an approach.
There are two broad families of ML benchmarks. First of all, a validator should change hyperparameters to verify the impact on the outcome as one moves through parameter space as well as what happens in edge cases where the model approaches the parameter space boundary. This analysis is therefore very much like how one would study the impact of changing the number of factors when validating a HW model for pricing Bermudan swaptions.
Simultaneously, when creating benchmarks it is also helpful to change the actual algorithm. Since many ML libraries have a standardized API to train models, creating benchmarks that are fundamentally different often does not require a large time investment. A good candidate benchmark model is a classification or regression tree because such model is very fast, and thanks to its simplicity, guarantees interpretability of the results.
Sensitivity testing
Sensitivity testing allows the validator to study the stability of the outcomes. Many ML packages use algorithmic differentiation which implies that we have the derivatives with respect to the model parameters without any effort.
Another aspect of sensitivity testing is to understand the sensitivity of the AI algorithm with respect to changes in the training data. As before, having a flexible way of creating alternative splits between train, validation and test datasets proves very valuable in this context.
Model uncertainty
A final aspect of this chapter on model design and performance testing is to quantify model uncertainty or model risk to measure the degree of unsureness in the modelling approach. As has been introduced by Knight,15 uncertainty is used when we do not have a probabilistic view on outcomes while risk is used when we have. In the latter case, we use risk management techniques such as diversification to manage risk. Irrespective of the case at hand, when quantifying model risk or model uncertainty the validator needs to have an understanding of the impact of changing model parameters as well as changing model assumptions.
Given that we have already explained how to perform sensitivity analysis, how to move through hyperparameter space and how to build alternative models by leveraging ML library APIs, quantifying model risk or uncertainty is simply a matter of applying the right formula to the various outcomes generated by these methods. In the context of risk, the standard approach is to integrate over parameter space and average over available models using Bayes rule.16 In the context of uncertainty, one often uses the so-called maxmin approach where the bank maximizes a robust version of expected utility which is the works-case expected outcome.17
14 Ren D., Amershi S., Lee B., Suh J., Williams J.D.
Squares: Supporting interactive performance analysis for multiclass classifiers IEEE TVCG, 23 (1) (2017), pp. 61-70
15 See Knight, F., “Risk, uncertainty and profit”, (1921) Boston: Houghton Mifflin
Model implementation testing
Model replication
The exact replication of an algorithm is non-trivial given the complexity of many ML approaches. This is why our suggestion is to rather look for an alternative implementation and compare the results. In case a proper sensitivity analysis has been performed, it is possible to determine quantitative statistical bounds on the expected difference between multiple implementations.
Code review
Most financial institutions leverage open source ML libraries that are being maintained by an active community. The custom code in many ML projects therefore mostly deals with data munging and feature selection, to prepare the data that is fed into the model itself. This part of the code should therefore be analyzed in most detail.
System implementation
Serving ML algorithms require extensive supporting technology to deal with large amounts of data and huge demand for computational power. Hence when analyzing the system implementation, particular care needs to be given towards how the platform scales. In addition, system monitoring is required to measure computational load as well as algorithmic behaviour. It should also be noted that both measures are often correlated since e.g. a problem in convergence often leads to higher demands for computational power.
The second point of attention is how the trained models are managed, especially in the context of dynamic calibration. In order to reproduce issues, one has to make sure that the order in which data is fed into the algorithm is persisted. Simultaneously, the algorithm’s state needs to be properly managed and audited by the ML platform to allow for troubleshooting.
16 See Cont R., “Model uncertainty and its impact on the pricing of derivative instruments.” (2006) Mathematical Finance, Wiley
17 See Gilboa & Schmeidler (1989) Maxmin expected utility with non-unique prior, Journal of mathematical economics
1.1.1. User acceptance testing
As with any software, user acceptance testing plays an important role. A good approach is to test the algorithm with a known dataset. A priceless source of information is Kaggle,18 which is a website that hosts data science competition. Kaggle’s site is a treasure trove of datasets as well as a massive number of algorithms that have been designed for a diverse set of modelling problems. Comparing the algorithm developed by the bank with a few alternative Kaggle scripts on one of their datasets is a quick way to gain insight into the proper functioning of the model.
1.1.2. Ongoing monitoring
We already mentioned that monitoring of the system and algorithmic health is critical in the context of productionizing AI applications. This is also why we believe that the regulators will require surveilling capabilities that surpass the current requirements on ongoing monitoring.
To do this properly, one has to define good KPIs that indicate model performance (see chapter 3.5 on Model design and performance testing). When anomalies on the KPIs are detected or when performance falls below a static threshold, a good monitoring system triggers alarms that can be logged in an issue tracking system. Ideally, model input is also monitored to detect changes in the data generating distribution which could move the algorithm into a regime that has not yet been studied.
Finally, critical ML algorithms require monitoring of model output as well. This can be done by detecting atypical behaviour in the output and by comparing results with a simpler model that can act as a real-time benchmark.
1.1.3. Understanding model limitations
Given the fact that machine learning algorithms are data-driven, model limitations can often be categorized through features of the input data. Ideally, a model validator wants to study the algorithm under a few different stressed conditions including:
These conditions can then be monitored to trigger alarms whenever boundaries on the viability of the datasets are reached.
- Small datasets
- Highly correlated input data
- Increasingly large amounts of noise
18 See www.kaggle.com
Conclusion
Since AI promises massive increases in efficiency and precision, many banks are starting various initiatives in this area. To be able to productionize ML algorithms, it is important that financial institutions understand the risks involved. In the present paper, we have studied these challenges through the lens of the model risk management framework, where we have highlighted the key differences compared to the management of more traditional models.
One of the main conclusions of this exercise is that ongoing monitoring of algorithms is even more critical since exhaustive testing of AI is impossible due to the dimensionality of the problem.
About the
Author(s)

Jos Gheerardyn is the co-founder and Chief Executive Officer (CEO) of Yields. Prior to his current role, he worked as both a manager and an analyst in the field of quantitative finance. With nearly 20 years of experience, he has worked with leading international investment banks and start-up companies. Jos is the author of multiple patents that apply quantitative risk management techniques to the energy balancing market. Jos holds a PhD in superstring theory from the University of Leuven.
