The most complete Model Risk Management software in the market
Manage your entire model lifecycle with award-winning Model Risk Management technology. Trusted by HSBC, BNP Paribas Personal Finance, Euroclear and 50+ leading financial institutions worldwide.




Why manual Model Risk Management
no longer works
Organisations rely on more models than ever, including AI influenced ones. Manual workflows make it difficult to keep oversight and maintain consistent governance. Yields brings structure and transparency and oversight to Model Risk Management.
Key features of our Model Risk Management Software
Our software brings structure to the full lifecycle and makes Model Risk Management easier to manage.
Central model inventory
Model risk assessment/ tiering
Model lifecycle overview
Workflow
engine
Documentation and evidence
Ongoing monitoring
Customize and configure in UX
Yields provides a centralized, configurable model inventory or model catalogue solution that gives you full visibility across all models, AI systems, and analytical tools throughout their lifecycle.
Assess model risk in a consistent and repeatable way. This helps prioritise reviews and make model risk decisions with confidence.
Manage the entire model lifecycle through standardized, auditable workflows that ensure consistency, accountability, and regulatory compliance from design and development to decommissioning.
Yields Model Risk Management software enables organisations to build and automate custom workflows, such as model validation, ensuring processes are consistent, scalable, and aligned with internal and regulatory requirements.
Generate all necessary Model Risk Management documentation and validation reports automatically in the Yields Model Risk Management Software.
Continuously track a model's performance, stability, and data quality over time to ensure it remains reliable and accurate after deployment.
Fully configurable by business users. Customize the solution by setting up workflows, controls, and governance yourself, no IT needed.
Collaboration across all lines of defence
Yields supports the full governance structure defined in the three lines of defence model. It helps each group work within their own responsibilities while staying aligned.
First line of defence
Use the platform to test, document and monitor models with clear ownership and traceability.
Second line of defence
Rely on structured workflows to validate models, assess risk, review assumptions and challenge outcomes.
Third line of defence
Audit the interaction between first and second line, perform independent investigations and identify residual risk.
Built for today’s model risk challenges
Explore how our software supports key model risk use cases, helping you manage complexity, ensure compliance, and stay in control.
Scale or outsource model validation
Manual validation processes slow you down and strain internal resources. Ensure independent, consistent, and scalable validation without operational bottlenecks.
Stay in control of model performance
Lack of continuous monitoring makes it hard to detect model drift and performance issues. Track, analyze, and act on model performance before it impacts outcomes.
Centralize model inventory
Without a centralized inventory, models remain fragmented and hard to govern. Gain full visibility and control over your entire model landscape.
Standardize model documentation
Inconsistent or incomplete documentation creates audit and compliance risks. Standardize and automate documentation to ensure clarity, traceability, and readiness.
Manage model risk at scale
Growing model complexity makes it difficult to maintain control and meet regulatory expectations. Establish a structured, scalable approach to managing model risk across your organization.
Manage models across the lifecycle
Disconnected processes lead to inefficiencies and lack of oversight. Manage the full model lifecycle from development to decommissioning in one controlled environment.
A structured Model Risk Management process
Model design and development
Centralized inventory, classification and risk tiers.
(pre)-Validation
Centralized inventory, classification and risk tiers.
Governance & attestation
Centralized inventory, classification and risk tiers.
Monitoring
Performance monitoring and model stability.
Change & version management
Controlled model changes, versioning and audit trail.
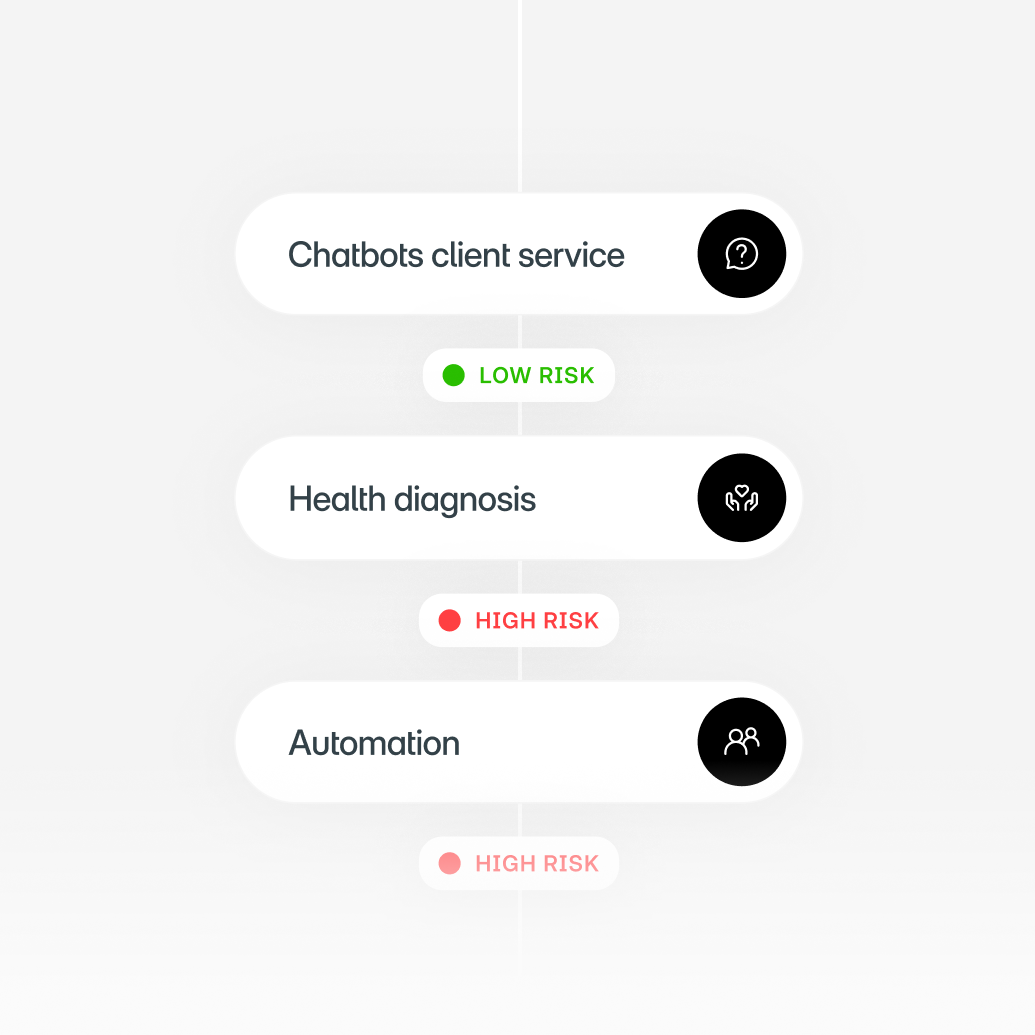
Where Model Risk Management meets AI
Models are evolving fast. Traditional analytical models are often replaced or enhanced by machine learning and AI techniques. Yields helps teams apply consistent Model Risk Management across all model types, even as methods change.
This keeps governance stable while the technology behind models evolves.
Proven results with Yields
These measurable improvements show how our Model Risk Management software transforms model governance.
Reduced validation time
Increased model performance
Reduced documentation time
Increased model validation productivity












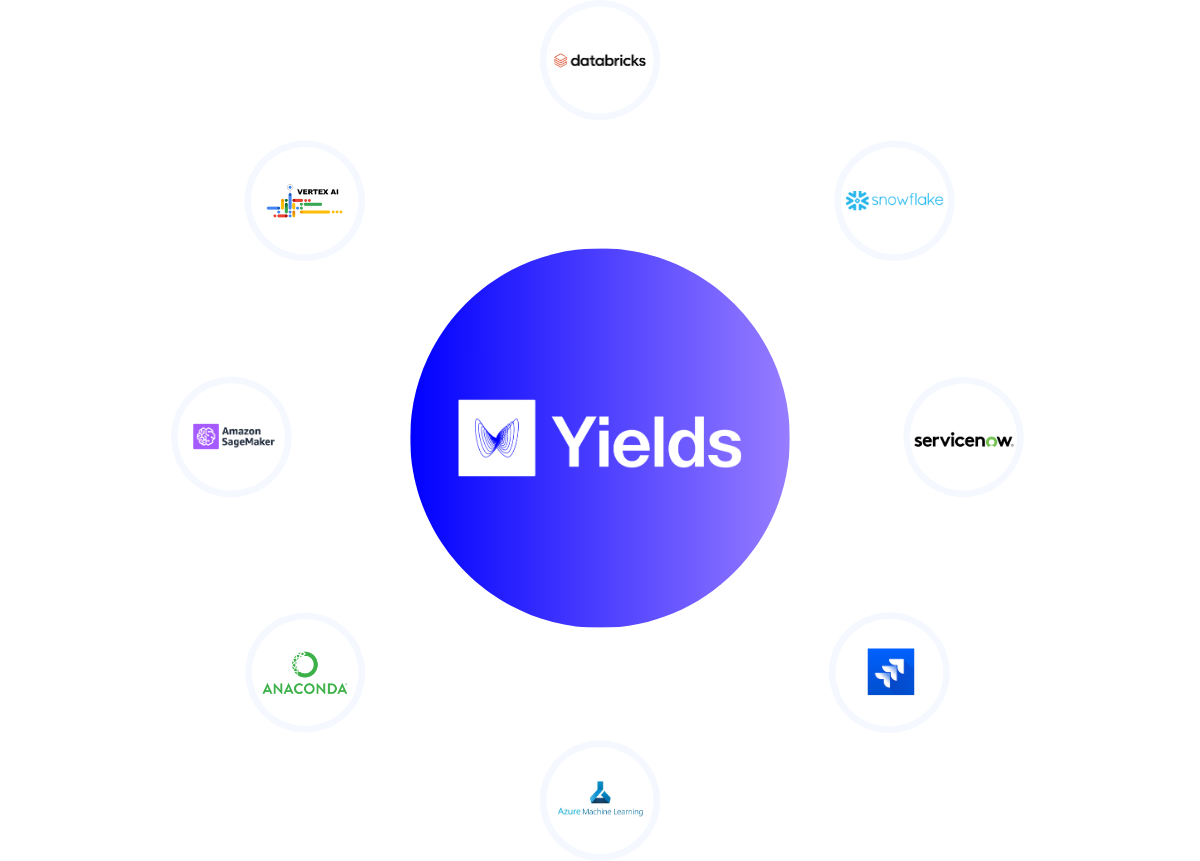
Connect Model Risk Management with your existing tools
Data, models and metrics already exist across many systems. Yields provides APIs and integrations that allow organisations to connect Model Risk Management software with their existing tooling.
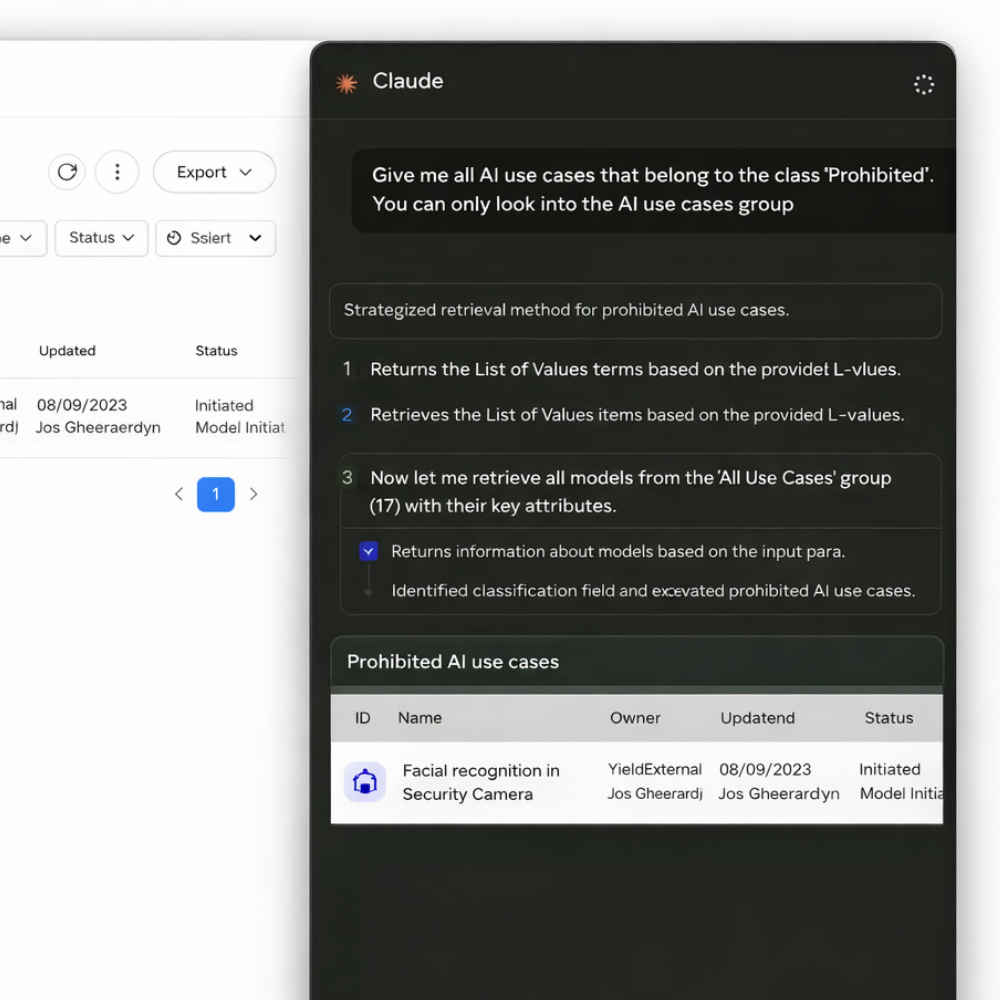
Access Yields through your favourite AI assistant
Yields can be connected to Large Language Models, allowing teams to interact with Model Risk Management data in new ways.
This features allows organisations to:
Query model inventories, documentation and risk data via LLMs.
Support analysis, reporting and exploration using AI assistants.
Enable controlled access to Model Risk Management information.
Combine human expertise with AI-driven support.
Ready to bring structure to your Model Risk Management process
See how Yields Model risk management software helps teams streamline validation, strengthen governance and create full oversight across all models.
.png)